Elevator Pitch
Part of the goal and progress of science is the reproduction of previous work and adaptation of it in order to further knowledge and further the findings. Often the lack of instruction, documentation, and comments in programs and algorithms produced in research hinder the adoption of these findings in future work.
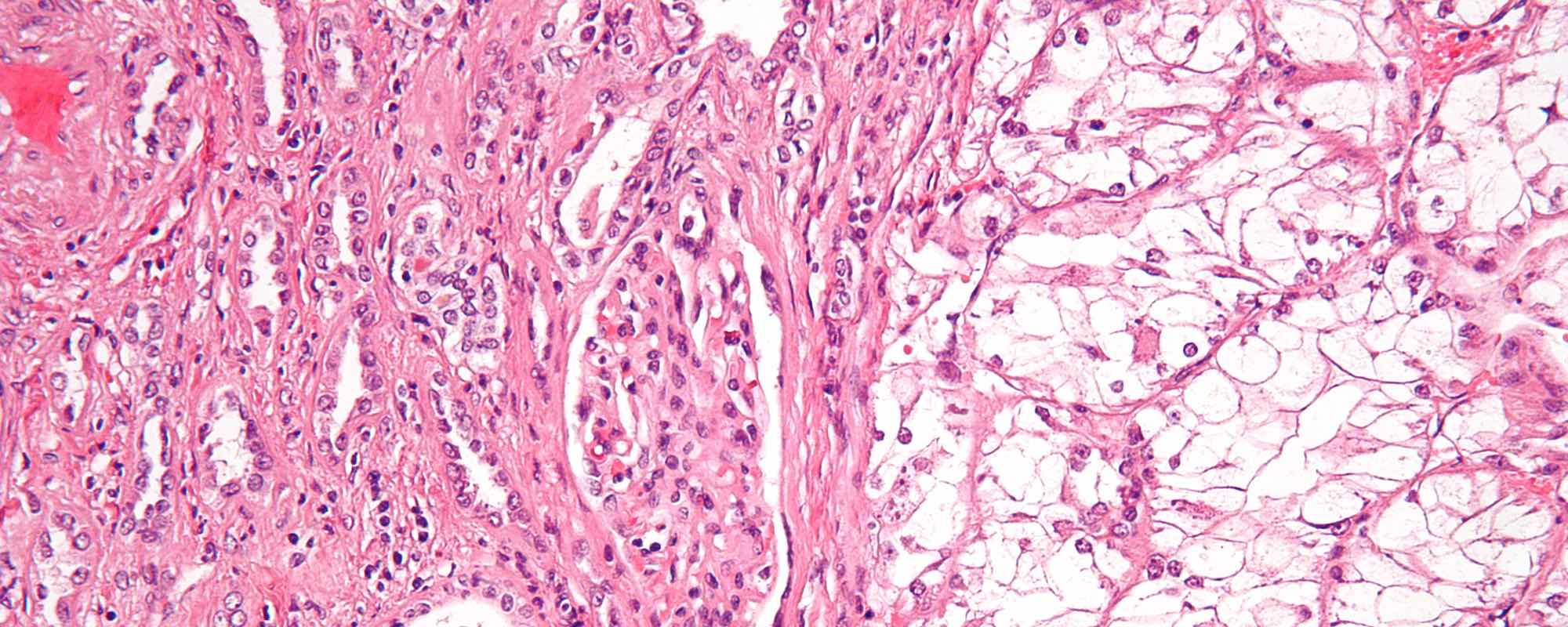
Histology is the study of tissue structure and often associated with microscopy and disease diagnosis such as cancer. Hematoxylin and eosin (H&E) stain is a principal technique for assisting pathologists in identifying structures in histology slides.
Under the guidance of Dr. Mark Zarella, I am reproducing the output of histology image processing algorithms designed to normalize and correct colors in H&E stained histology images. The goal of this work will aid in cancer diagnosis with the ultimate goal of earlier diagnosis and increased survival rates. Based on the knowledge I will gain reproducing the original research findings, I will document the inputs and outputs of the algorithms while developing instructional materials to aid other researchers and doctors in the use and application of the algorithms.
The original work is created using proprietary software which may exclude some researchers. I intend to reproduce the algorithms in a language that is platform agnostic and unencumbered by license restrictions, notably Python, to allow them to be used by a wider range of interested parties.
Poster
Lesson Plan
- Unit: Big Data/Algorithms
- Subject/Course: JavaScript/Algorithms
- Grade Level: College
- Preparation Time: 1 hour
- Estimated Length: 2.5 hours
Objectives
Students will be able to:
Summarize the usage and relevance of machine learning algorithms such as SVM and kmeans and explain how they relate to predictive computer programs.
Social Impact/Relevance
Using computers to make predictions in a given problem space is essential in allowing expert knowledge to scale. For instance, in the field of cancer diagnosis, prediction is generally made by a human expert after reviewing a tissue sample (histological slide) and assessing the relative arrangements of tissue structures such as cell nuclei. Creating computer algorithms that can rate probabilities based on a digital version of the same slide can reduce the burden on high level expert staff the time necessary to diagnose cancer by allowing experts to focus only images with high probability or ambiguous structures. In resource restricted environments, this could also allow a few experts to treat many more patients.
Assessment Evidence
Students will engage in classroom discussion and submit a written discussion about problems that can be solved using machine learning.
Students will take a quiz on basic machine learning concepts.
Lesson Activity/Outline
The lesson will begin with an overview of separating data. Students will see data sets that can be split using lines on a cartesian plane. This will lead to a discussion of the ideas of supervised vs unsupervised learning and a the workings of kmeans and SVM algorithms.
Using a pre-created dataset of movies, students will rate movies that they have seen as “liked” or “disliked”. This will create a training data set that can be fed to a pre-created program used to make predictions about other movies that the student might like or dislike. Students will select a list of 10 movies they have seen to test the program’s accuracy. As students rate more movies, the program should increase in accuracy. Thus they will begin to understand the concepts of training sets, testing sets, and prediction as well as the importance of having large data sets when working with machine learning algorithms.
Teacher Reflection Notes
Can also work well in an online setting particularly if the program can be converted to a web based application.
Modifications, accommodations
With proper data sets this could be adjusted to work with music, books or other media.